Offensichtlich hat es bei der Google Suche eine Änderung gegeben. Der SEO-Tool-Anbieter Sistrix schreibt darüber in seinem Blog. Demnach sinkt die Zahl der einzelnen Webseiten einer Domain im Gesamtbestand bei Google. Bei großen News-Sites mit Millionen einzelnen Webdokumenten wird das deutlich.
Je mehr, desto besser war eigentlich immer das Credo bei der Erstellung von Content. Man versucht mehr Seiten in den Google-Index zu bringen. Dadurch steigt die Chance, dass User durch Sucheingaben auf so eine Seite kommen und die ganze Domain dadurch „sichtbarer“ wird.
Jetzt zeigt sich – zumindest für einige große Sites -, dass die Anzahl der Seiten pro Domain im Index der Seiten eher kleiner wird. Möglicherweise crawlt Google nur noch wirklich relevante Seiten und eben keine veralteten oder irrelevanten mehr. Den Sistrix-Beitrag findest du hier.
Wenn wieder einmal ein Google Webmaster Hangout mit John Mueller für das DACH-Gebiet stattfindet, kann man diese Frage ja einmal stellen. Was bisher dort verlautete war, dass das sogenannte Crawling-Budget für kleine und mittelgroße Sites überhaupt kein Problem ausmacht. Dagegen empfehlen Suchmaschinenoptimierer aber sehr wohl, auf das Crawling-Budget zu achten, damit man sichergehe, dass auch nur die relevanten Seiten, die man wirklich im Index haben will, dort eingehen und nicht aus „Budgetgründen“ hinten herunter fallen.
In der Praxis heißt das, irrelevante Seiten müsste man löschen. Andererseits ist die Google-Suche auch nicht immer das Maß aller Dinge. Verlage haben so die Chance, durch eigene Suchfeatures diese von Google nun vielleicht unbeachteten Seiten in ihrem Auftritt zugänglich zu machen.
Die Meinungen gehen derzeit noch auseinander, aber insgesamt passt die Reduzierung eines Indexumfangs ins Bild: Google versucht, die Interessen mobiler User besser zu bedienen. Unterwegs, mit dem Smartphone, braucht man nur ein oder zwei Sätze als Erklärung für eine Suchanfrage. Idealerweise lässt man das auch noch automatisch vorlesen. Das tiefe Schürfen in Archiven ist da eben nicht gefragt (auch das wäre eine Chance für alternative Suchanbieter).
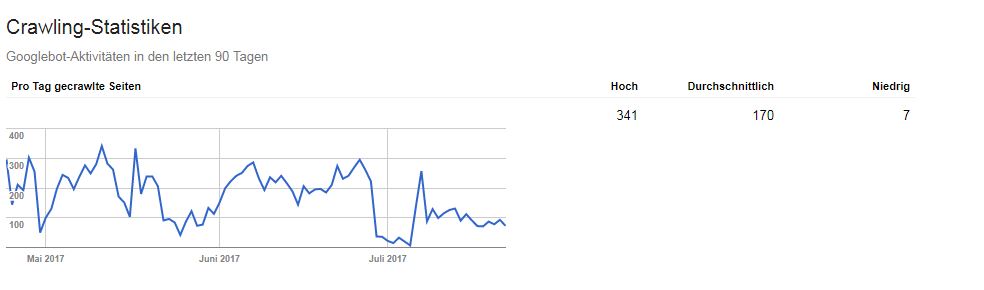
Dennoch: Wir Webseitenbetreiber sind aufgeschreckt. Was tun wir? Wir schauen in die Angaben in den Google Webmaster Tools, aka Google Search Console. Du findest den Abschnitt „Crawling Statistiken“ unter dem Hauptmenüpunkt „Crawling“.
Du kannst die Anzahl der Ergebnisse im Index auch durch die Google-Suche schätzen lassen. Tippe site:https://www.deine-domain.cc ein (statt deine-domain.cc setzt du natürlich deine eigene Domain ein, oder die, die dich interessiert). Auf der Suchergebnisseite wird oben eine Zahl ausgegeben. Auch wenn dies kein exakter Wert ist, wird er wohl eine Annäherung darstellen.
Wenn du also eine Website mit 1.000 Einzelseiten hast und du erhälst nur 10 oder 20 Seiten als Ausgabe, dann sieh nach, was falsch läuft. Eine XML-Sitemap kann helfen. Möglicherweise blockiert ein übermotivierter oder sehr konservativer Administrator auch einige Ressourcen, absichtlich oder unabsichtlich. Admins denken immer mal, „das geht keinen was an“ – hinterher kommt der Google-Crawler aber nicht mehr an die Seiten heran.
Fazit
Solltest du noch kein Webmaster/Search Console-Konto haben, lege eines an. Es kostet nichts. Du musst deine Site nur validieren, bestätigen, dass du der Webmaster bist, sozusagen.
Google warnt dich auch, wenn jemand deine Site gehackt hat oder etwas anderes schief läuft. Außerdem siehst du, mit welchen Begriffen deine Seite als Ergebnis in der Google-Suche ausgegeben wird und wieviele Leute darauf klicken. Ähnliche Statistiken gibt es auch für Bing und Yandex.